
Welcome to the BASICS Toolkit
The BASICS Toolkit is part of the BASICS research project (Borrowing of Argument Structure in Contact Situations: The Case of Medieval English under French influence). The project is a cooperation between researchers from the English Department at the University of Mannheim (Carola Trips, Michael Percillier) and the Romance Department at the University of Stuttgart (Achim Stein, Yela Schauwecker). The project is funded by the German Research Foundation (Deutsche Forschungsgemeinschaft – DFG) for a six-year period (2015–2021).
The project investigates grammatical change in the medieval language contact situation between English and French which arose after the Norman Conquest (1066 until ca 1500). The domain of research consists of structural borrowing phenomena and their connection with the lexicon: massive borrowing of lexical items with a predicate-argument structure is hypothesised to have favoured and produced grammatical changes. Therefore, the phenomenon in focus is the borrowing into medieval English of French verbs and the question of how their argument structure has influenced its grammar. By taking into account lexical-semantic theories, findings about language acquisition and the sociolinguistic background, the project will provide new insights into the process of structural borrowing, and into how to distinguish internal from contact-induced language change.
The BASICS Toolkit combines the software tools and resources created and used in the framework of the project. The various components are accessible via the navigation bar at the top of the page. A brief description of each tool is given below, with more detailed information and instructions on the respective pages.
-
Verb classes
A searchable catalogue of verb classes as defined by Levin (1993).
-
Reverse lookup
A tool to perform a reverse lookup of Present-Day English verbs in the Middle English Dictionary.
-
Lemma search
A utility to search a database of form-lemma correspondences for verbs in the PPCME2, PCMEP, and PLAEME corpora.
-
Lemmatizer
A script to insert lemma information for verbs in the PPCME2, PCMEP, or PLAEME corpora.
-
qMaker
A tool to generate a CorpusSearch query file from a list of Middle English verbs.
-
penn2svg
A tool to generate graphical syntactic trees in the SVG format from a CorpusSearch output file.
The workflow in which the tools are used is charted and commented below.
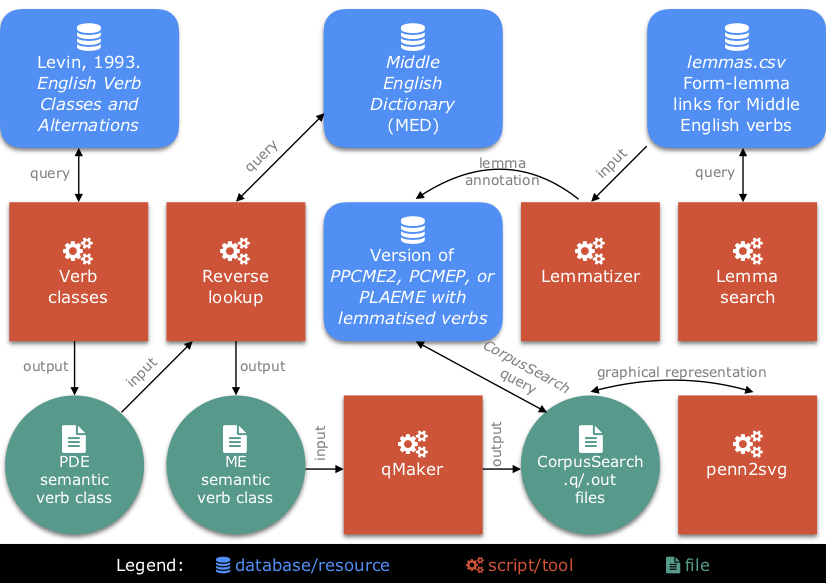
The main objective of the workflow is to query Middle English (ME) semantic verb classes in order to investigate their argument structures.
The first step is therefore to define semantic verb classes. A standard reference for English verb classes is Beth Levin's 1993 monograph English Verb Classes and Alternations, which groups Present-Day English (PDE) verbs into semantic classes and lists possible argument structures for each class. The tool Verb classes allows queries in a digital index of Levin (1993). The results of such queries are saved in a HTML file containing the corresponding PDE semantic verb classes. As Levin's verb classes relate to PDE only, their ME equivalents have to be determined. The tool Reverse lookup uses the PDE semantic verb classes as input to query the Middle English Dictionary (MED, McSparran et al. 2001), returning any ME verbs in whose definitions the queried PDE verbs occur. This output is saved as HTML and CSV files, which once verified constitute the ME semantic verb classes corresponding to the original input from Levin (1993).
In order to query these ME semantic verb classes in a ME corpus, the verbs in this corpus need to be lemmatized. This is achieved by creating a database of form-lemma links for ME verbs, stored in a file called lemmas.csv. This inventory can be searched with the Lemma search tool. The tool Lemmatizer uses lemmas.csv to insert verb lemma information into the PPCME2 (Penn-Parsed Corpus of Middle English, Second Edition, Kroch & Taylor 2000), the PCMEP (Parsed Corpus of Middle English Poetry, Zimmermann 2018), or PLAEME (Parsed Linguistic Atlas of Early Middle English, Truswell et al. 2018). The inserted lemma information consists of the verb lemma for each verb, and a unique numerical verb identifier ("MED-ID") as used in the MED.
With a ME corpus containing lemmatized verbs, the ME semantic verb classes can be queried in the corpus. This is achieved with CorpusSearch (Randall 2010). The tool qMaker uses the ME semantic verb classes as input to generate a corresponding CorpusSearch .q file, with which the PPCME2/PCMEP/PLAEME can be queried. The output of this query is saved as a CorpusSearch .out file. In order to facilitate the verification and analysis of this output, the Penn-Treebank format of the .out file can be represented graphically in the SVG format with help of the penn2svg tool.